Jeśli chcesz używać Linuksa do świadczenia usług dla firmy, usługi te będą musiały być bezpieczne, odporne i skalowalne. Ładne słowa, ale co rozumiemy przez nie??
‘Bezpieczne’ oznacza, że użytkownicy mogą uzyskać dostęp do potrzebnych im danych, czy to tylko do odczytu, czy do zapisu. Jednocześnie żadne dane nie są ujawniane żadnym podmiotom, które’nie ma uprawnień, aby to zobaczyć. Bezpieczeństwo jest zwodnicze: możesz myśleć, że masz wszystko zabezpieczone, ale później dowiesz się, że są dziury. Projektowanie w zakresie bezpieczeństwa od początku projektu jest znacznie łatwiejsze niż próba późniejszego doposażenia.
‘Sprężysty’ oznacza, że Twoje usługi tolerują awarie w infrastrukturze. Awarią może być kontroler dysku serwera, który nie może już uzyskać dostępu do żadnych dysków, co powoduje, że dane są nieosiągalne. Lub awarią może być przełącznik sieciowy, który nie umożliwia już komunikacji między dwoma lub więcej systemami. W tym kontekście: “pojedynczy punkt awarii” lub SPOF to awaria, która negatywnie wpływa na dostępność usługi. Odporna infrastruktura to taka bez SPOF.
‘Skalowalny’ opisuje zdolność systemów do płynnego radzenia sobie ze skokami popytu. To także określa, jak łatwo można wprowadzać zmiany w systemach. Na przykład dodanie nowego użytkownika, zwiększenie pojemności pamięci lub przeniesienie infrastruktury z Amazon Web Services do Google Cloud – a nawet przeniesienie jej we własnym zakresie.
Gdy tylko twoja infrastruktura rozszerzy się poza jeden serwer, istnieje wiele opcji zwiększania bezpieczeństwa, odporności i skalowalności. My’Przyjrzyjmy się, jak te problemy zostały tradycyjnie rozwiązane, oraz jakie nowe technologie są dostępne, które zmieniają oblicze dużych aplikacji.
Aby zrozumieć co’jest możliwe dzisiaj, to’pomocne jest spojrzenie na tradycyjną realizację projektów technologicznych. W dawnych czasach – to znaczy ponad 10 lat temu – firmy kupowałyby lub wynajmowały sprzęt do uruchamiania wszystkich komponentów swoich aplikacji. Nawet stosunkowo proste aplikacje, takie jak witryna WordPress, mają wiele składników. W przypadku WordPress potrzebna jest baza danych MySQL wraz z serwerem internetowym, takim jak Apache, oraz sposób obsługi kodu PHP. Więc oni’d zbuduj serwer, skonfiguruj Apache, PHP i MySQL, zainstaluj WordPress i wyłącz je’d idź.
Ogólnie rzecz biorąc, to działało. Działało to na tyle dobrze, że wciąż istnieje ogromna liczba serwerów skonfigurowanych dokładnie w ten sposób. Ale nie było’Idealny, a dwa większe problemy to odporność i skalowalność.
Brak odporności oznaczał, że każdy znaczący problem na serwerze spowodowałby utratę usługi. Najwyraźniej katastrofalna awaria oznaczałaby brak strony internetowej, ale nie było też miejsca na przeprowadzenie zaplanowanej konserwacji bez wpływu na stronę internetową. Nawet instalacja i aktywacja rutynowej aktualizacji zabezpieczeń dla Apache wymagałaby kilku sekund’ awaria witryny.
Problem odporności został w dużej mierze rozwiązany poprzez budowę ‘klastry o wysokiej dostępności’. Zasadą było, aby dwa serwery działały na tej stronie, skonfigurowane w taki sposób, że awaria jednego z nich nie uległa awarii’t powoduje awarię witryny. Świadczona usługa była odporna, nawet jeśli nie działały poszczególne serwery.
Streszczenie chmury
Częścią Kubernetes jest abstrakcja, którą oferuje. Od programisty’z punktu widzenia opracowują aplikację do działania w kontenerze Docker. Docker nie’nie obchodzi mnie to’działa w systemie Windows, Linux lub innym systemie operacyjnym. Ten sam kontener Docker można pobrać od dewelopera’s MacBook i działaj pod Kubernetes bez żadnych modyfikacji.
Sama instalacja Kubernetes może być pojedynczą maszyną. Oczywiście wiele korzyści z Kubernetes wygrało’t być dostępne: nie będzie automatycznego skalowania; tam’jest oczywistym pojedynczym punktem awarii i tak dalej. Jednak jako dowód koncepcji w środowisku testowym działa.
Kiedyś’gotowy do produkcji, możesz uruchomić w domu lub u dostawcy usług w chmurze, takiego jak AWS lub Google Cloud. Dostawcy chmury mają pewne wbudowane usługi, które pomagają w uruchomieniu Kubernetes, ale żadna z nich nie jest trudna. Jeśli chcesz poruszać się między Google, Amazon i własną infrastrukturą, konfigurujesz Kubernetes i poruszasz się. Żadna z Twoich aplikacji nie musi się w żaden sposób zmieniać.
A gdzie jest Linux? Kubernetes działa na systemie Linux, ale system operacyjny jest niewidoczny dla aplikacji. Jest to znaczący krok w dojrzałości i użyteczności infrastruktur IT.
Efekt Slashdot
Problem skalowalności jest nieco trudniejszy. Pozwolić’Powiedzmy, że Twoja witryna WordPress odwiedza 1000 osób miesięcznie. Pewnego dnia Twoja firma jest wymieniona w Radio 4 lub telewizji śniadaniowej. Nagle dostajesz ponad miesiąc’w ciągu 20 minut. My’wszyscy słyszeliśmy historie stron internetowych ‘upaść’, i to’s zazwyczaj dlaczego: brak skalowalności.
Dwa serwery, które pomogły w zapewnieniu odporności, mogły poradzić sobie z większym obciążeniem niż sam jeden serwer, ale to’wciąż jest ograniczony. ty’d zapłacę za dwa serwery w 100 procentach przypadków i przez większość czasu oba działają idealnie. To’jest prawdopodobne, że ktoś sam może uruchomić Twoją witrynę. Następnie John Humphrys wspomina o Twojej firmie na Today and you’d potrzebuję 10 serwerów do obsługi obciążenia – ale tylko przez kilka godzin.
Lepszym rozwiązaniem problemu odporności i skalowalności było przetwarzanie w chmurze. Skonfiguruj instancję serwera lub dwa – małe serwery, na których działają Twoje aplikacje – w Amazon Web Services (AWS) lub Google Cloud, a jeśli jedna z instancji z jakiegoś powodu ulegnie awarii, zostanie automatycznie uruchomiona ponownie. Skonfiguruj poprawnie automatyczne skalowanie, a gdy Humphrys sprawi, że obciążenie wystąpień na twoim serwerze WWW gwałtownie wzrośnie, automatycznie zostaną uruchomione dodatkowe wystąpienia serwera, aby podzielić obciążenie. Później, gdy odsetki maleją, dodatkowe instancje zostają zatrzymane, a Ty płacisz tylko za to, czego używasz. Doskonały… Albo to jest?
Chociaż rozwiązanie w chmurze jest znacznie bardziej elastyczne niż tradycyjny autonomiczny serwer, nadal występują problemy. Aktualizowanie wszystkich działających instancji chmury nie jest’t proste. Tworzenie aplikacji w chmurze również wiąże się z pewnymi wyzwaniami: laptop, którego używają programiści, może być podobny do wystąpienia chmury, ale tak jest’to nie to samo. Jeśli zdecydujesz się na AWS, migracja do Google Cloud jest złożonym przedsięwzięciem. Przypuśćmy, że z jakiegoś powodu po prostu to robisz’nie chcę przekazywać twoich danych do Amazon, Google lub Microsoft?
Kontenery pojawiły się jako sposób na zawinięcie aplikacji wraz ze wszystkimi ich zależnościami w jeden pakiet, który można uruchomić w dowolnym miejscu. Kontenery, takie jak Docker, mogą działać na programistach’ laptopy w taki sam sposób, w jaki działają w instancjach chmurowych, ale zarządzanie flotą kontenerów staje się coraz trudniejsze wraz ze wzrostem liczby kontenerów.
Odpowiedzią jest orkiestracja kontenerów. To znacząca zmiana ostrości. Wcześniej upewnialiśmy się, że mamy wystarczającą liczbę serwerów, fizycznych lub wirtualnych, aby zapewnić obsługę obciążenia. Korzystanie z dostawców chmury’ automatyczne skalowanie pomogło, ale nadal mieliśmy do czynienia z instancjami. Musieliśmy ręcznie skonfigurować moduły równoważące obciążenie, zapory ogniowe, przechowywanie danych i inne. Dzięki aranżacji kontenerów wszystko (i wiele więcej) jest załatwione. Określamy wymagane wyniki, a nasze narzędzia do aranżacji kontenerów spełniają nasze wymagania. Określamy, co chcemy zrobić, a nie jak chcemy to zrobić.
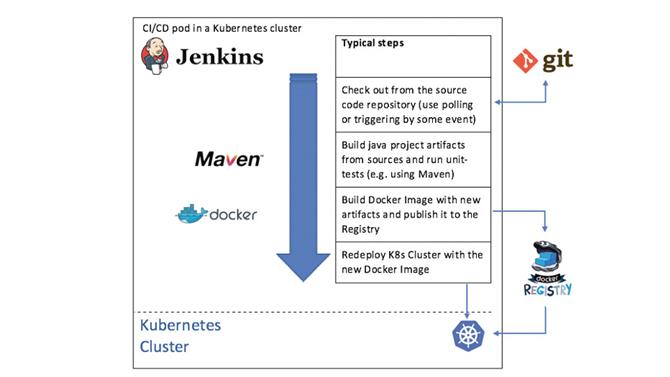
Ciągła integracja i ciągłe wdrażanie może dobrze współpracować z Kubernetes. Tutaj’przegląd Jenkinsa używanego do budowy i wdrażania aplikacji Java
(Źródło zdjęcia: Future)
Zostań Kubernete
Kubernetes (ku-ber-net-eez) jest obecnie wiodącym narzędziem do aranżacji kontenerów i pochodzi od Google. Jeśli ktoś wie, jak zarządzać wielkoskalową infrastrukturą IT, Google wie. Pochodzenie Kubernetes to Borg, wewnętrzny projekt Google, który’są nadal używane do uruchamiania większości Google’aplikacje, w tym wyszukiwarka, Gmail, Mapy Google i inne. Borg był tajemnicą, dopóki Google nie opublikował artykułu na ten temat w 2015 r., Ale artykuł wyraźnie pokazał, że Borg był główną inspiracją dla Kubernetes.
Borg to system zarządzający zasobami obliczeniowymi w Google’s centrów danych i utrzymuje Google’Aplikacje, zarówno produkcyjne, jak i inne, działają pomimo awarii sprzętu, wyczerpania zasobów lub innych problemów, które mogłyby spowodować awarię. Dokonuje tego, uważnie monitorując tysiące węzłów tworzących Borga “komórka” oraz kontenery na nich uruchomione oraz uruchamianie lub zatrzymywanie kontenerów zgodnie z wymaganiami w odpowiedzi na problemy lub wahania ładunku.
Sam Kubernetes narodził się z Google’s GIFEE (‘Google’s Infrastruktura dla każdego innego’) i została zaprojektowana jako przyjazna wersja Borg, która może być przydatna poza Google. Został przekazany na rzecz Linux Foundation w 2015 r. Poprzez utworzenie Cloud Native Computing Foundation (CNCF).
Kubernetes zapewnia system, dzięki któremu Ty “ogłosić” konteneryzowanych aplikacji i usług oraz zapewnia, że aplikacje działają zgodnie z tymi deklaracjami. Jeśli twoje programy wymagają zewnętrznych zasobów, takich jak pamięć masowa lub usługi równoważenia obciążenia, Kubernetes może zapewnić te zasoby automatycznie. Może skalować aplikacje w górę lub w dół, aby nadążać za zmianami obciążenia, a nawet skalować cały klaster, gdy jest to wymagane. Twój program’komponenty don’Muszę nawet wiedzieć, gdzie oni’ponownie uruchomiony: Kubernetes zapewnia wewnętrzne usługi nazewnictwa dla aplikacji, aby mogły się z nimi połączyć “wp_mysql” i automatycznie połączony z właściwym zasobem.’
Efektem końcowym jest platforma, za pomocą której można uruchamiać aplikacje w dowolnej infrastrukturze, od pojedynczej maszyny, przez lokalny stelaż systemów, aż po oparte na chmurze floty maszyn wirtualnych działających na dowolnym dużym dostawcy chmury, wszystkie przy użyciu tych samych kontenerów i konfiguracja. Kubernetes jest niezależny od dostawcy: uruchom go gdziekolwiek chcesz.
Kubernetes to potężne narzędzie i niekoniecznie jest złożone. Zanim przejdziemy do przeglądu, musimy wprowadzić kilka terminów używanych w Kubernetes. Kontenery uruchamiają pojedyncze aplikacje, jak omówiono powyżej, i są pogrupowane w zasobniki. Kapsuła to grupa ściśle powiązanych kontenerów rozmieszczonych razem na tym samym hoście i współdzielących niektóre zasoby. Pojemniki w kapsule działają jako zespół: oni’Będę wykonywać powiązane funkcje, takie jak kontener aplikacji i kontener rejestrowania z określonymi ustawieniami dla aplikacji.
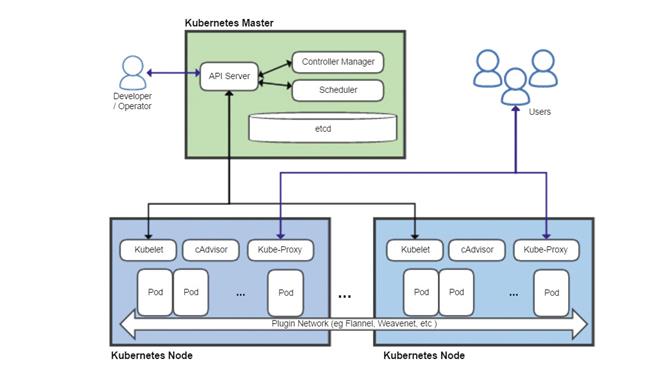
Przegląd Kubernetes pokazujący wzorzec z kluczowymi komponentami i dwoma węzłami. Należy zauważyć, że w praktyce główne elementy mogą być podzielone na wiele systemów
(Źródło zdjęcia: Future)
Cztery kluczowe komponenty Kubernetes to Serwer API, Harmonogram, Menedżer Kontrolera i rozproszona baza danych konfiguracji o nazwie etcd. Serwer API jest sercem Kubernetes i działa jako główny punkt końcowy dla wszystkich żądań zarządzania. Mogą być one generowane z różnych źródeł, w tym z innych komponentów Kubernetes, takich jak harmonogram, administratorzy za pośrednictwem linii poleceń lub pulpitów nawigacyjnych oraz same aplikacje w kontenerach. Sprawdza poprawność żądań i aktualizuje dane przechowywane w etcd.
Program planujący określa, na których węzłach będą uruchamiane różne moduły, biorąc pod uwagę ograniczenia, takie jak wymagania dotyczące zasobów, ograniczenia sprzętowe lub programowe, obciążenie pracą, terminy i więcej.
Menedżer kontrolerów monitoruje stan klastra i spróbuje uruchomić lub zatrzymać podsystemy, jeśli to konieczne, za pośrednictwem serwera API, aby doprowadzić klaster do pożądanego stanu. Zarządza także niektórymi połączeniami wewnętrznymi i funkcjami bezpieczeństwa.
Każdy węzeł uruchamia proces Kubelet, który komunikuje się z serwerem API i zarządza kontenerami – zwykle za pomocą Dockera – oraz Kube-Proxy, który obsługuje proxy sieci i równoważenie obciążenia w klastrze.
Rozproszony system baz danych etcd wywodzi swoją nazwę od /itp folder w systemach Linux, który służy do przechowywania informacji o konfiguracji systemu oraz przyrostka ‘re’, często używany do oznaczenia procesu demona. Celem etcd jest przechowywanie danych klucz-wartość w sposób rozproszony, spójny i odporny na uszkodzenia.
Serwer API przechowuje wszystkie swoje dane stanu w etcd i może jednocześnie uruchamiać wiele instancji. Program planujący i menedżer kontrolera może mieć tylko jedną aktywną instancję, ale korzysta z systemu dzierżawy w celu ustalenia, która z uruchomionych instancji jest główną. Wszystko to oznacza, że Kubernetes może działać jako system o wysokiej dostępności bez pojedynczych punktów awarii.
Kładąc wszystko razem
Jak zatem wykorzystujemy te komponenty w praktyce? Poniżej znajduje się przykład konfiguracji witryny WordPress przy użyciu Kubernetes. Jeśli chcesz to zrobić naprawdę, to ty’d prawdopodobnie używa predefiniowanego przepisu zwanego tabelą sterów. Są dostępne dla wielu popularnych aplikacji, ale tutaj my’Przyjrzyjmy się niektórym krokom niezbędnym do uruchomienia witryny WordPress na Kubernetes.
Pierwszym zadaniem jest zdefiniowanie hasła do MySQL:
kubectl utwórz tajny ogólny mysql-pass –from-literal = hasło = YOUR_PASSWORD
kubectl porozmawia z serwerem API, który zweryfikuje polecenie, a następnie zapisze hasło w etcd. Nasze usługi są zdefiniowane w plikach YAML, a teraz potrzebujemy trwałego miejsca do przechowywania danych w bazie danych MySQL.
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: mysql-pv-Claitbels: app: wordpressspec: accessModes: – ReadWriteOnceresources: żądania: pamięć: 20Gi
Specyfikacja powinna być w większości oczywista. Pola nazwy i etykiety służą do odwoływania się do tego magazynu z innych części Kubernetes, w tym przypadku z naszego kontenera WordPress.
Kiedyś my’Po zdefiniowaniu pamięci możemy zdefiniować instancję MySQL, wskazując ją na predefiniowaną pamięć. Że’Następnie należy zdefiniować samą bazę danych. Dajemy tej bazie danych nazwę i etykietę dla łatwego dostępu w Kubernetes.
Teraz potrzebujemy innego kontenera do uruchomienia WordPress. Część specyfikacji wdrażania kontenera to:
rodzaj: Deploymentmetadata: name: wordpresslabels: app: wordpressspec: strategia: typ: Odtwórz
Rodzaj strategii “Odtwarzać” oznacza, że jeśli dowolny kod składający się na aplikację ulegnie zmianie, działające instancje zostaną usunięte i ponownie utworzone. Inne opcje obejmują możliwość cyklicznego włączania nowych instancji i usuwania istniejących, jeden po drugim, umożliwiając kontynuowanie działania usługi podczas wdrażania aktualizacji. Wreszcie deklarujemy usługę dla samego WordPressa, obejmującą kod PHP i Apache. Część pliku YAML deklarująca to:
metadane: nazwa: wordpresslabels: aplikacja: wordpressspec: porty: – port: 80selector: aplikacja: wordpresstier: frontendtype: LoadBalancer
Zwróć uwagę na ostatni wiersz, definiujący typ usługi jako LoadBalancer. To instruuje Kubernetes, aby usługa była dostępna poza Kubernetes. Bez tej linii byłoby to po prostu wewnętrzne “Tylko Kubernetes” usługa. I to’s to. Kubernetes użyje teraz tych plików YAML jako deklaracji tego, co jest wymagane, i skonfiguruje zasobniki, połączenia, pamięć itd., Zgodnie z wymaganiami, aby wprowadzić klaster do “pożądany” stan.
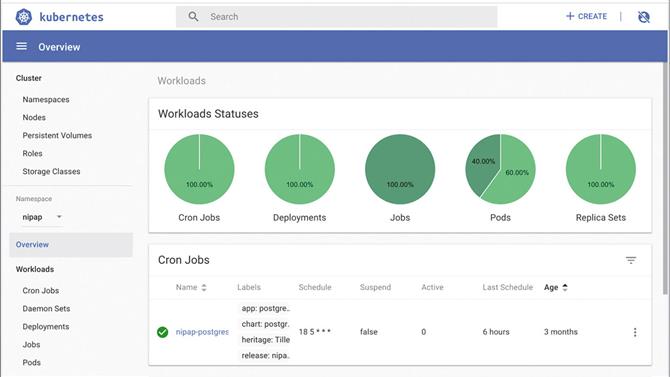
Skorzystaj z widoku pulpitu nawigacyjnego, aby uzyskać podsumowanie działania Kubernetes w skrócie
(Źródło zdjęcia: Ditching)
To koniecznie był tylko ogólny przegląd Kubernetes, a wiele szczegółów i funkcji systemu zostało pominiętych. My’przeskoczyliśmy o automatycznym skalowaniu (zarówno zasobnikach, jak i węzłach tworzących klaster), zadaniach cron (uruchamianie kontenerów zgodnie z harmonogramem), Ingress (równoważenie obciążenia HTTP, przepisywanie i odciążanie SSL), RBAC (kontrola dostępu oparta na rolach), sieć zasady (zapora ogniowa) i wiele innych. Kubernetes jest niezwykle elastyczny i niezwykle wydajny: w przypadku każdej nowej infrastruktury IT musi być poważnym konkurentem.
Zasoby
Jeśli ty’nie znasz Dockera, zacznij tutaj: https://docs.docker.com/get-started.
Tam’interaktywny samouczek dotyczący wdrażania i skalowania aplikacji tutaj: https://kubernetes.io/docs/tutorials/kubernetes-basics.
I zobacz https://kubernetes.io/docs/setup/scratch, aby dowiedzieć się, jak zbudować klaster.
Możesz grać w bezpłatny klaster Kubernetes na https://tryk8s.com.
Na koniec możesz przemyśleć długi, techniczny dokument z doskonałym przeglądem Google’Wykorzystanie Borga i jak to wpłynęło na projekt Kubernetes tutaj: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43438.pdf.
Dowiedz się więcej o Tiger Computing.
- Najlepsze miejsce do przechowywania w chmurze w 2019 r. Online: opcje bezpłatne, płatne i biznesowe